Refactoring Legacy Javascript: Part 1
Enter the haunted forest
My workplace has the expected share of legacy code, and one piece nestles at the heart of a major product I supported for years as a developer. This very successful product dates back to when the company was a frantic handful of developers trying to do too much work in too little time, and by the time I joined the company it had attained nigh-on haunted graveyard status. Little documentation, no tests, a tangled mess of tightly-dependent code in at least three languages, relied upon daily by many Important Clients.
One of my first tasks was a backlog ticket to add an insignificant feature to this product, and it took me a full month to feel like I understood it well enough to not break it. (Spoiler: even then I didn’t understand it.) Over the years tiny changes broke production more often than not, and every developer who touched it had to spend days chasing down arcane undocumented trivia, like how to even build the localization files.
Did I mention no tests?
Of course I adopted this orphaned codebase as my ugly, precious baby. I spent many hours thinking about how to make it beautiful, even while knowing it would never be a priority. At one point I demanded the opportunity to refactor the entire PHP codebase for testability as a prerequisite for adding a new feature, but the Javascript was deemed out of scope. None of us had a background in Javascript development, and the code worked until now, might as well just cross our fingers and hope it held out until this product’s inevitable retirement.
The problem with decade-old Javascript, however, is that the browser landscape keeps changing, and suddenly you get an emergency bug ticket from an Important Client because your product doesn’t work in a new browser. And nobody understands how the code works, or how to test it, or where the script to build the localization files lives.
I didn’t get that ticket because I’ve moved on to another role, so I only watched Slack in dismay as the dev described a week struggling to implement and verify a ten-line fix, some of which could have been avoided if I’d documented my own fights more thoroughly. (She is a better dev than I, and wrote down the entire elaborate build process as she figured it out.)
The purpose of refactoring
If you’re not familiar with a language, figuring out how to write tests or run the code can be an insurmountable barrier. The curse of haunted Javascript is that all today’s snazzy test frameworks assume you are using modern techniques like modules or ES6 syntax or a framework. Nothing like that in legacy files! Only a bunch of functions, dumped into an inline script tag.
You can’t get code coverage unless you can require your files in your tests, and you can’t tell what parts of the 3000-line monolith to put in a module.exports without either writing a test, or painstakingly stepping through in a way no one ever seems to have the time for. Last year I spent a weekend trying to get at least a test framework running, and ended up lost in the bowels of Istanbul source code.
But improving the code coverage metrics is just something I want to do. There are some genuine reasons to want to modernize the code to do things like remove global variables, but even that is mostly personal preference. The real problem is that it takes too long to check if your changes worked.
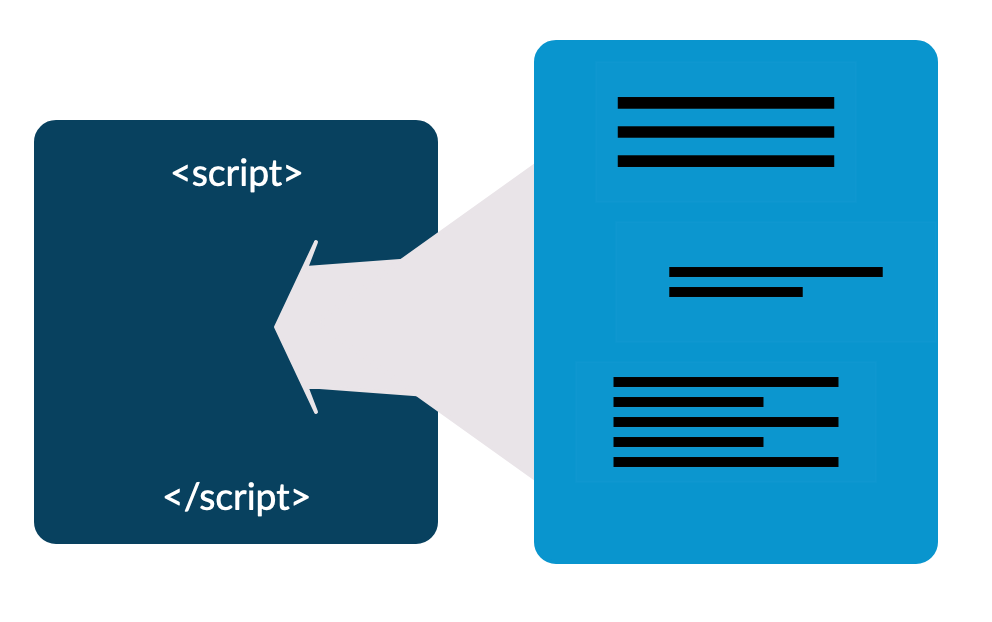
I came back to this on Tuesday full of renewed determination to make the process of building and testing this code easier. Right now “the process” involves running two different command line scripts manually and checking in the processed artifacts. These artifacts are dynamically injected into a <script> tag at run time.
Let’s draw that as a picture:
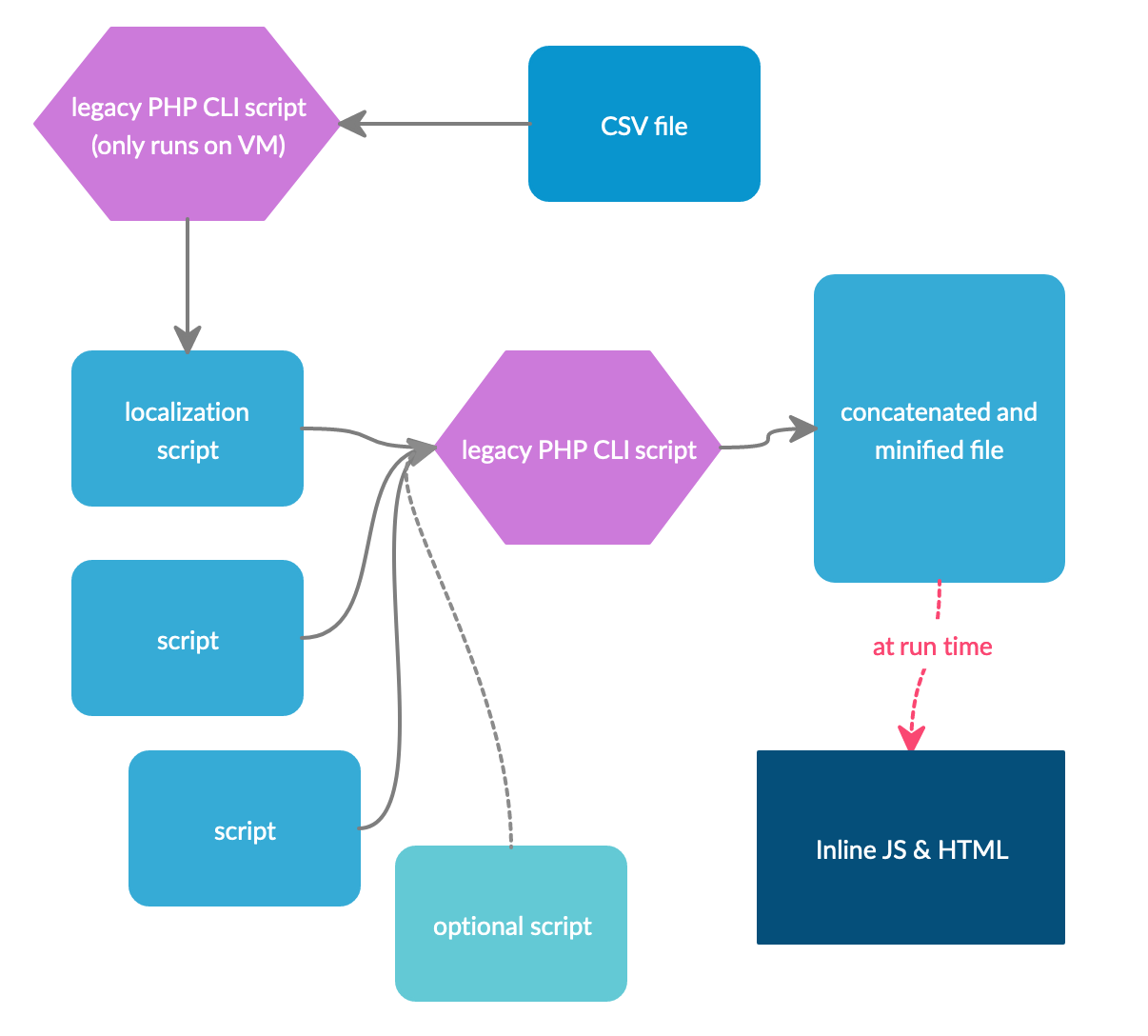
This diagram makes it look more straightforward than it is currently:
- Every one of these files lives in a different directory
- There are several customer-specific builds, which require passing command-line parameters to the manual scripts
- One of the scripts can only be run in a VM environment, and getting the processed file back to your laptop is complicated.
How can we make this easier?
First I decided on my goals:
- A developer new to this project should be able to build a testable artifact in one step after making a code change
- The whole build should be able to run on different environments—developer laptop, VM, or CI pipeline—without a lot of custom setup
- The build should allow us to move a lot of these steps to the existing automated build pipeline
- Artifacts produced by this new build process should be identical to the old process
- None of the existing files should be changed
The last one is possibly overkill, but I want to be absolutely sure that my desire to improve the developer experience doesn’t impact the actual production code.
Choosing tools
First things first, we need a package manager. I went with npm over yarn because I’ve used npm before and it’s already installed on my computer. At least one other project also uses npm, so it’s pretty likely to be on other developers' computers too.
Running tasks
For my needs I knew I wanted to use a task runner. As I said before, I am not a Javascript expert, and neither are the people who maintain this product. There aren’t many other Javascript projects in the company that I can use for reference, and I’m not familiar with the common Javascript toolchain.
I considered using a custom script or a task runner in another language—gradle is commonly used even for projects that aren’t Java. I decided to pick a JS tool despite that for a few reasons:
- Custom scripts are how we got in this mess—if you spend enough time to make a script that’s resilient and extendable, you’ve basically written another task runner. Better to use one that’s actively maintained.
- A tool that’s designed to work with Javascript is more likely to have built-in support for the kind of steps used in Javascript pipelines, like running Google Closure Compiler.
- I hold a grudge against Gradle after years of having to deal with build chains I didn’t understand.
- I wanted to learn more about Javascript toolchains.
A quick search for Javascript build tools got me a few options:
Webpack
- PRO: Used by another project at work; might have some crossover expertise
- PRO: Extremely popular
- CON: Primary use case is transpiling modern syntax into backwards-compatible Javascript; almost no references found for how to use it without transpiling
Gulp
- PRO: Very fast
- CON: Relatively complicated to use
Grunt
- PRO: Described as simpler to learn than Gulp
- CON: I can’t remember, but surely there was something?
Webpack was clearly out because it is a bundler, not a task runner, and trying to force it to be a task runner would lead to heartache. Grunt and Gulp seemed to be a toss-up, with some articles describing Grunt having more a focus on configuration, and Gulp more on programming. I decided to try Gulp first, for nebulous reasons including the fact that it was supposed to be faster, and I didn’t like the Grunt logo.
I fully planned to delete Gulp if I got frustrated with it, because there are clearly other options that work very well.
Next steps
In the next post I’ll talk about how I set up a working build script in 4 hours, and then spent until sunrise debugging a single configuration option.